Refactoring des Angular Web-Portals von smartmove: Ein Post-Mortem
Eine der größten Herausforderungen, über die kaum jemand wirklich spricht, ist es, ein bestehendes Projekt an die Hand zu bekommen und dieses nicht komplett neu zu programmieren, sondern es im laufenden Betrieb zu überarbeiten. In diesem Fall hat man nicht den Luxus, von Grund auf eine Architektur zu planen. Wer kennt es nicht: Allzu oft ist auch die zugehörige Dokumentation nur stellenweise hilfreich und frühere Teams sind bereits mit zwei Schritten zur Tür hinaus.
Der nachfolgende Blogpost ist daher nicht dazu gedacht, die technischen Details einzelner Code-Implementierungen zu beleuchten, sondern soll vielmehr einen Überblick schaffen, wie ein existierendes Projekt in geregelter Art und Weise verbessert werden kann und welche Gedankengänge diesem Vorgang zugrunde liegen.
Doch wo zieht man hier die Grenze? Wann lohnt es sich, mit einer existierenden Codebase weiterzuarbeiten, anstatt mit einer weißen Weste zu beginnen?
Die Mondlandung: Der erste Kontakt mit dem Projekt
Als ich zum ersten Mal einen Blick auf das Web Portal von smartmove werfen konnte, sah ich bereits einen sehr soliden Kern. Man hatte sich offenbar zu einer logischen Modularisierung Gedanken gemacht, dazugehöriges Routing passend implementiert. Es war recht schnell klar, dass hier Know-How aus dem Mobilitätssektor eingeflossen war, um die einzelnen Teilbereiche des Angular-Projekts zu definieren und abzustecken. Viele Features funktionierten, die Webapp hatte bereits einige KundInnen gesehen und Arbeit geleistet.
Recht schnell zeigten sich aber auch erste Pain-Points: Das Ziel eines Programmierers sollte immer sein, Code zu entwickeln, der wartbar, skalierbar und möglichst wiederverwendbar ist, doch nur zu oft sieht man sich in existierenden Projekten mit einer anderen Realität konfrontiert. Mein Mentor vor einigen Jahren nannte solche Repositories gerne “organisch gewachsen”; Dies bedeutet kurzum, dass die ursprüngliche, erdachte Struktur noch zu erkennen ist, doch liegt sie teilweise begraben unter einem Wuchs an Bugfixes und kurzfristig angesetzten Entscheidungen.
An dieser Stelle sei gesagt, dass ein erfahrener Programmierer versuchen sollte, nicht vorschnell über vorliegende Code-Projekte zu urteilen. Nur zu oft sind die Gründe hinter manchen seltsam wirkenden Strukturen in diesen “organisch gewachsenen Projekten” nicht einfach erkennbar, selbst wenn darauf geachtet wurde, In-Line Kommentare zu hinterlassen. Die Skripte, die für uns undurchsichtig erscheinen, wurden vielleicht in der Vergangenheit genutzt, um obskuren, heute unbekannten Anforderungen gerecht zu werden. Es ist daher nicht immer die beste Idee, ganze Script-Blöcke herauszureißen und sie neu zu schreiben, selbst wenn das Entwirren mancher Komponenten wie eine fürchterliche Sisyphusarbeit erscheint. Allzu oft riskieren wir in so einem Fall, alte Bugfixes zu entsorgen.
Wenn es der Zeitplan zulässt, empfehle ich auch immer, einige kleine Bugfixes anzugehen. Hier ist das Ziel nicht die Verbesserung des Projektes, sondern vielmehr die Möglichkeit, anhand eines praktischen Beispiels ein wenig Überblick zu gewinnen. Wie “fließt” der Code durch die Applikation, welche Coding Patterns wiederholen sich immer wieder? Sobald man ein Gefühl für diese Fragen entwickelt hat, wirken zukünftige Aufräumarbeiten schon weitaus weniger nebulös.
Die größten Problemherde identifizieren
Wie weiter oben bereits erwähnt, hatten meine Vorgänger des existierenden Projekts zum Web Portal von smartmove bereits auf eine thematisch sinnvolle Kompartmentalisierung geachtet. Bereiche wie Fahrzeuge, Buchungen und Kundendaten waren in ihre eigenen sinnvollen Module unterteilt.
Innerhalb dieser Module, auf dem Hierarchielevel einzelner Komponenten und Frontend-Services, gab es allerdings Verbesserungsbedarf in zwei recht grob zu deklarierenden Punkten:
-
Services
Auch wenn der Versuch gemacht wurde, Singleton-Strukturen für übergeordnete Prozeduren und Funktionen zu erschaffen (z.B. zur Handhabe von verschiedenen Fahrzeuglisten), war offenbar über Zeit eine große Menge an spezifischer Logik aus verschiedenen Bereichen in diese Singletons gewandert. Das Ergebnis waren viele aufgeblasene Services, die eine klare Kompetenztrennung benötigten. -
Komponenten
Im Bereich einzelner Komponenten bestand oft ein recht unklarer Fluss von Daten, ein Umstand, der durch die Nutzung einer Third-Party User-Interface Lösung zusätzlich verschlimmert wurde. Es war selten wirklich klar, welche Komponenten sich mit reinem UI beschäftigen sollten und in welchen Arealen die Business Logik angesiedelt war. An vielen Stellen verschwammen diese beiden Teile ineinander, nahezu untrennbar verbunden durch Code, der zusätzlich dafür sorgen musste, die erwähnte Third-Party UI-Lösung in die passende Form zu pressen.
Beide diese Themen erschienen wichtig, doch die Services taten zumindest ihren Dienst und kamen neuen Features selten in die Quere. Schon nach kurzer Zeit kristallisierte sich die unzureichend aufgetrennte Architektur auf Komponenten-Ebene als größere Problematik heraus, insbesondere auch vor dem Hintergrund der oben angesprochenen Dreifaltigkeit aus Wartbarkeit, Skalierbarkeit und Wiederverwendung.
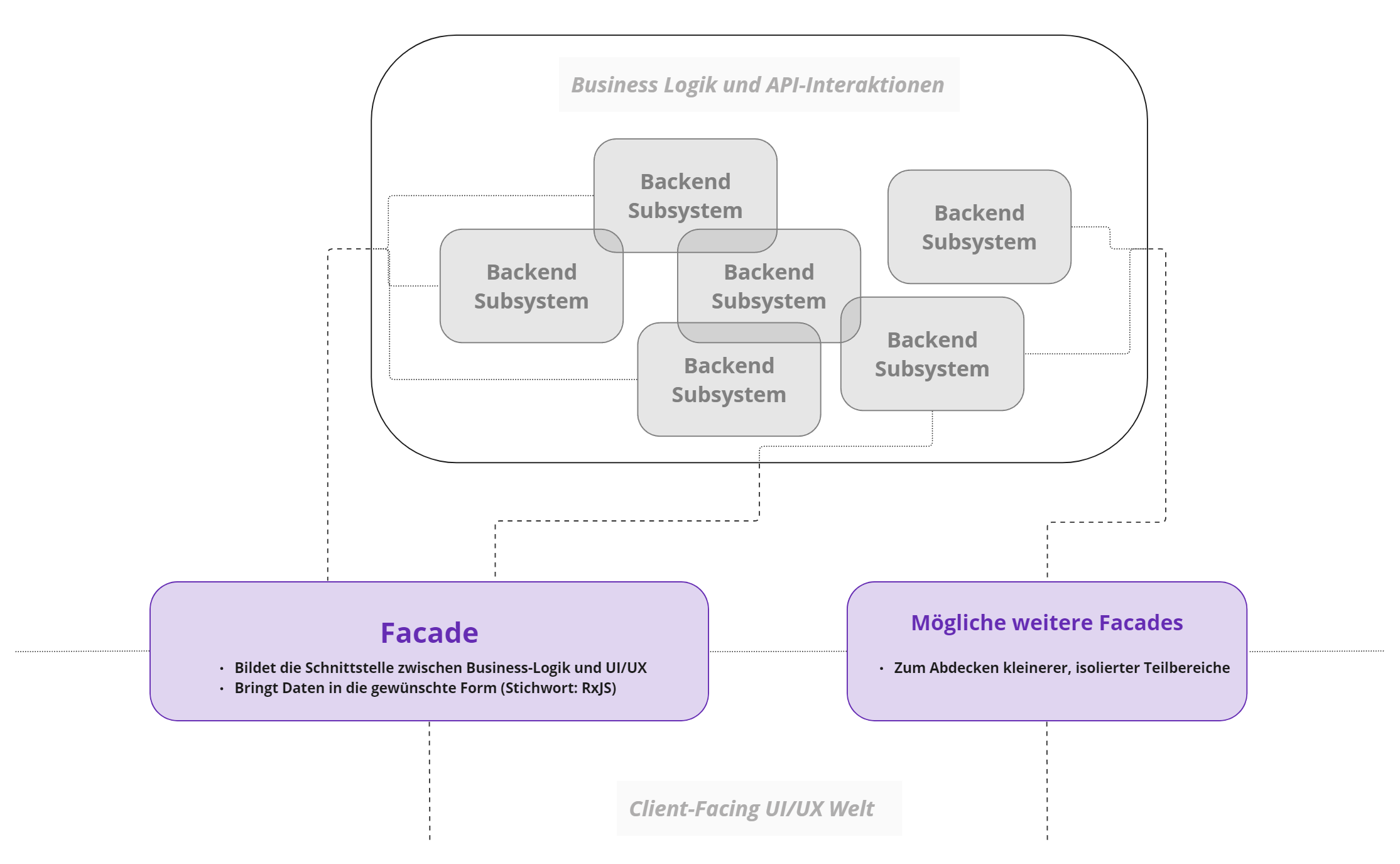
Die Lösung, Teil 1: Das Facade-Pattern
Nach Sichtung der in der letzten Sektion aufgelisteten
Problemstellen folgte eine recht rasche Brainstorming-Phase, um
mögliche Lösungen zu evaluieren. Die Wahl fiel, nach einem
kurzen, erfolgreichen Testlauf anhand eines neuen Features, auf
eine Implementierung basierend auf dem Facade Software Pattern.
Sehr einfach erklärt erlaubt das Facade Pattern es, eine Art
Zwischenebene einzuziehen, die komplexen, oft verwirrenden Code
versteckt. Zu vergleichen ist dies mit der Fassade eines Hauses,
unter der allerlei Verstrebungen, Rohre und Kabel liegen
können.
Eine Fassade unterstützt somit die Trennung von Client-Facing,
möglichst simplen UI Komponenten
(Stichwort: dumb components) und der involvierten
Business Logik.
Durch die von einer Fassade klar deklarierte Grenze wurde es bedeutend einfacher, den Code existierender Komponenten einer ersten Aufteilung zu unterziehen, doch damit alleine war es nicht getan.
Die Lösung, Teil 2: Smart and Dumb Components
Im Laufe der Refactoring-Arbeit wurde relativ schnell klar, dass
Fassaden alleine nicht unser gewünschtes Ergebnis liefern
würden. Bei der Umstrukturierung existierenden Codes lag unser
Fokus auf simplen, wiederverwendbaren Komponenten, die im besten
Falle ausschließlich zum Anzeigen von User Interface dienen
sollten. Doch gerade diese Komponenten sollten nicht direkt mit
der implementierten Fassade interagieren oder selbst die
benötigten Anzeigedaten erfragen.
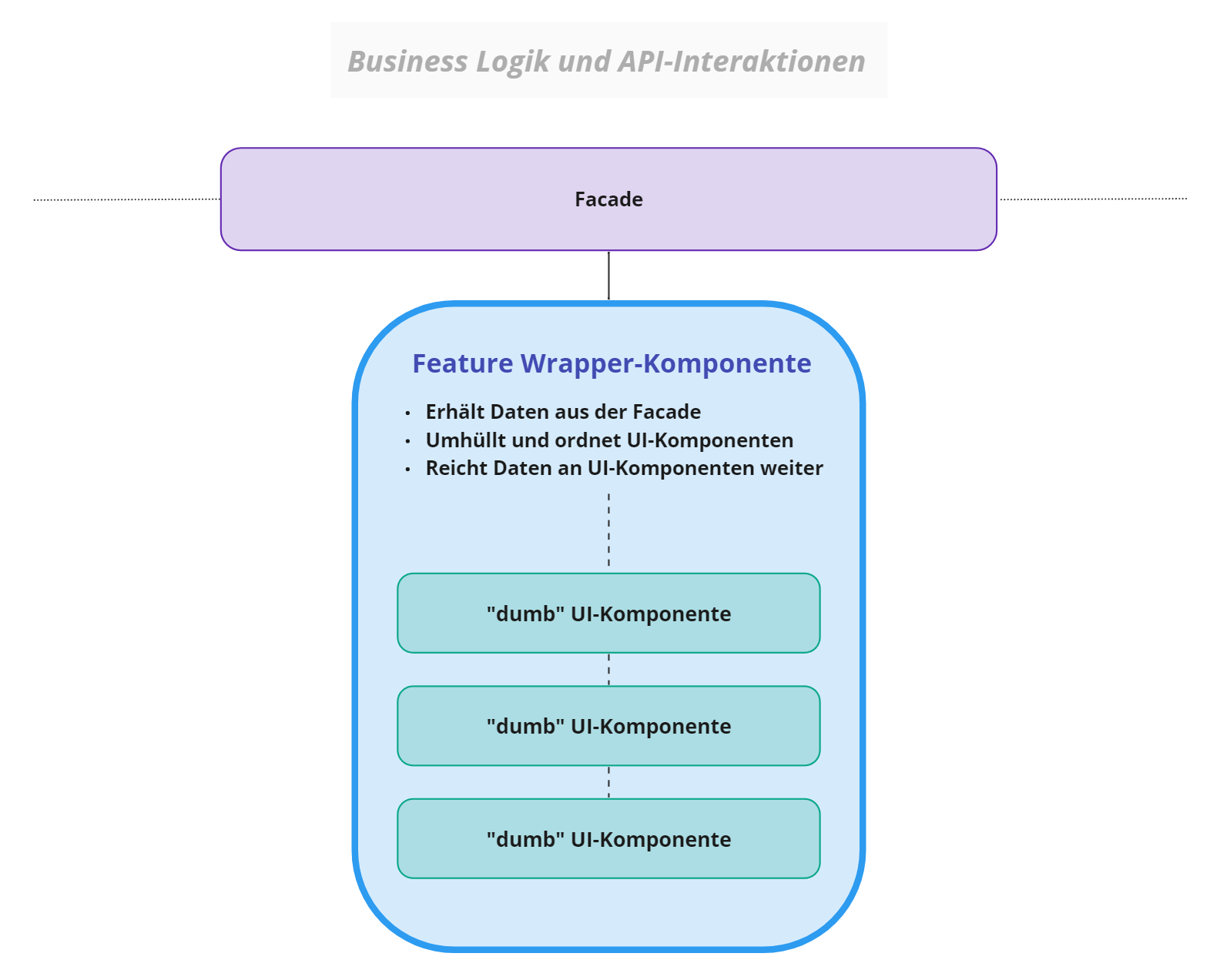
Es benötigte daher eine einzelne Kommandozentrale, eine Smart
Component für jedes Feature, deren Aufgabe es war, mit der
Fassade zu interagieren. Zusätzlich war diese Wrapper-Komponente
für die Komposition der “dummen” UI-Components zuständig: Daten
sollten von der Fassade in die Wrapper-Komponente fließen,
welche wiederum die einzelnen UI-Teile umhüllte und die nötigen
Daten weiter nach unten verteilte.
Auf diese Art konnte der Bereich vor der Fassade gut gehandhabt werden, doch woher kamen die erwähnten Daten? Was passierte mit dem Code, der nun hinter der Fassade versteckt war?
Die Lösung, Teil 3: Buddy-Services
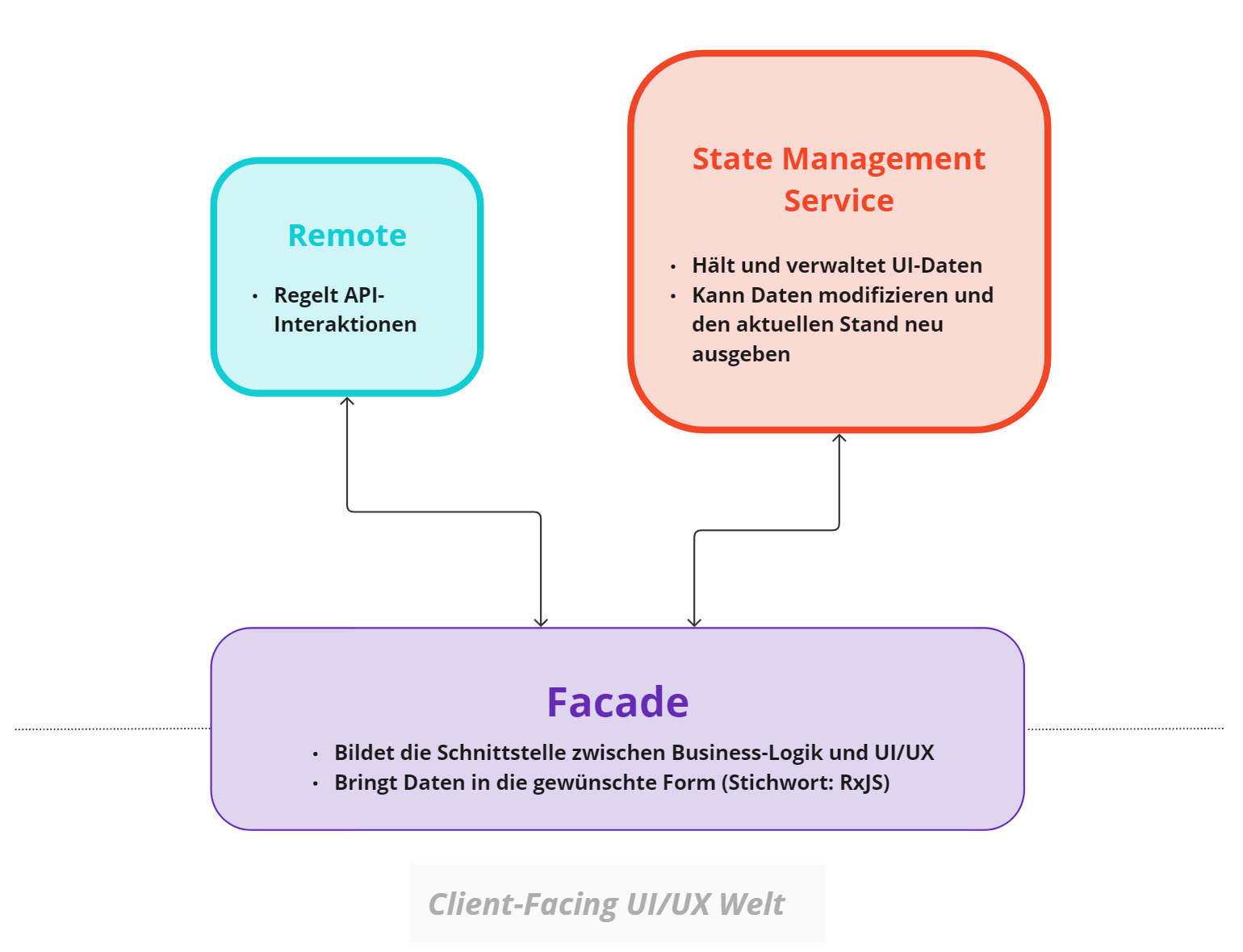
Während im ersten Anlauf, wie bereits beschrieben, eine Fassade genutzt wurde, um komplexen Code einfacher zugänglich zu machen, sollte danach auch der Bereich hinter der Fassade einer Strukturierung unterzogen werden. Jede Fassade erhielt einen zusätzlichen kleinen Buddy-Service, der sich ausschließlich mit der Backend/API-Interaktion beschäftigen sollte: Die Remote. Vorteil dieser Remote war es, eine klare Anlaufstelle für Backend-Frontend Interaktion zu liefern, was wiederum das Finden möglicher Bugs in diesem Bereich vereinfachte. Zugang zur Remote (und damit zu jeglichen API-Interaktionen) sollte ausschließlich über die Fassade stattfinden.
Zusätzlich benötigten einige Features die Möglichkeit, den Zustand ihres jeweiligen User Interfaces und der zugrunde liegenden Daten entsprechend anzufragen. Diese Features wurden daher mit einem weiteren Buddy-Service der Fassade ausgestattet: dem State Management Service. Dieser Bereich beschäftigte sich mit der Handhabe und Verwaltung eines feature-spezifischen UI-Modells. Nur hier konnten Daten verändert und neu ausgesendet werden, in der restlichen Feature-Struktur wurden Informationen schlicht durchgeleitet und in Form gebracht, aber niemals verändert. Indem wir die Veränderung von Daten derart limitierten, konnten wir garantieren, dass in anderen Bereichen des Codes keine unerwünschten Nebeneffekte weitergeleitet wurden. Daten flossen nun von unserem State Management Service durch die Fassade in die zentrale Wrapper-Komponente, um von dort auf die darunter liegenden UI-Komponenten verteilt zu werden. Durch diese aufgebaute Architektur wird jede Komponente, die über unsere zentrale Schnittstelle mit der Fassade interagiert, immer Zugriff auf dieselbe, aktuelle Instanz des UI-Zustandes haben.
Bottom-Line: Die Arbeit ist nie zu Ende
Die Implementierung der oben erläuterten Struktur machte sich schnell bezahlt:
- Die Wartbarkeit und Handhabe von überarbeiteten Bereichen wurde um ein Vielfaches einfacher - sowohl für UI-spezifische Bugs, als auch für Probleme mit der Business Logik.
- Die erklärte Architektur bildete eine Blaupause, eine klare, nachvollziehbare Herangehensweise und für das Refaktorieren und die Aufteilung weiterer bereits existierender Features. Die Grundfunktionen zum Verwalten des UI-Modells wurden in einen abstrakten Kern verpackt, um jedem feature-spezifischen State Management Service dasselbe Set an Werkzeugen bieten zu können.
- Unerwünschte, UI-basierte Nebeneffekte konnten auf ein Minimum reduziert werden, da der aktuelle Zustand des User Interfaces von einem State-Service verwaltet wird.
- Da sowohl überarbeitete als auch neue Features nun der gleichen, simplen Struktur mit klarem Datenfluss und Kernbereichen folgten, wurde das Finden von Bugs und die Einschulung weiterer Programmierer stark erleichtert.
An dieser Stelle sei jedoch gesagt, dass trotz all dieser Änderungen und Verbesserungen noch lange nicht alles getan war: Wie oben bereits erwähnt, gab es noch einige bestehende Services, die unter der Last ihrer angesammelten Methoden litten. Ein großer Bereich des Web-Portales war außerdem immer noch an jene Third-Party UI-Solution gebunden, auch wenn diese nun nur noch in den klar abgetrennten Client-Facing Bereichen ihr Unwesen trieb.
Unsere Fassade-Basierte Architektur war der erste, große Schritt, denn die klare Aufteilung des Codes machte es einfacher, die nun strukturierten Komponenten Stück für Stück heran zu ziehen und zu überarbeiten, ohne dabei einen großen, ungewollten Kaskaden-Effekt zu riskieren.
Wer sich weiterführende Gedanken machen möchte, kann sich an dieser Stelle über die Konzeptionierung eigener generalisierter, wiederverwendbarer UI-Komponenten informieren - die von uns genutzte Lösung, um die im Web Portal vorliegenden Third-Party UI-Komponenten vollständig ersetzen zu können.
Wir sehen uns im nächsten Blogpost!